Henrik Hautop Lund, Orazio Miglino, Luigi Pagliarini, Aude Billard, Auke Ijspeert
Abstract--- We explore the concept of development without programming by children. Especially, we look at the case of developing robot control systems. The evolutionary robotics approach has shown that in some cases, given a mathematically described fitness function, it is possible to achieve an automatic development of robot controllers. However, it is questionable how one is to construct the mathematical fitness function. So we applied an interactive genetic algorithm to the problem of developing robot controllers and achieved an evolutionary robotics approach that allows children without any programming knowledge to develop controllers for LEGO robots. We used neural networks as robot controllers, and found that combining the interactive genetic algorithm with a kind of reinforcement learning -- development at the evolutionary time scale combined with lifetime development -- reduces the development time dras tically. Hence, we overcome one of the major drawbacks of the interactive genetic algorithm, namely the development time.
In recent years, we have shown different properties of the evolutionary robotics approach at the IEEE ICEC conferences. Initially, we [5] showed how to evolve robot controllers in simulation before transferring the evolved robot controllers to the real robot in the real environment and achieve very similar performance. In this work, we argued that for the simulationreality transfer it is advantageous to use control systems that allow generalisation over noise and other discrepancies between the simulator and the real world. Therefore, we used neural networks as control systems for the robot in that study. Secondly, we [1], [4] showed how it is possible to coevolve robot controllers and robot body plans. Some of this work was done in simulation only, because of the difficulties in designing selfmodifying hardware. However, we showed in [4] how to modify preamplifiers, synthesizers, and mixers in an auditory system for a mobile robot. Our argument was that one can coevolve robot controllers and robot body plans in simulation, build the physical robot according to the evolved robot body plans, download the evolved control system, and then observe a real robot behaviour similar to the one in simulation. At least, the simulator should be sufficient to describe the nearoptimal robot body plan for a specific task. The LEGO robot simulator that we describe in this paper will act as a test for this hypothesis. Finally, we [3] showed how to evolve sufficient neural network controllers for specific tasks, and we [2] designed an approach to evolve complex robot behaviours without a monolithic fitness function. This was achieved by designing an evolvable behaviorbased system, in which primitives for simple behaviours were evolved first, and then arbitrators were evolved to decide which primitives to perform at each given moment. In all these evolutionary robotics studies presented at the IEEE ICEC conferences and in our other evolutionary robotics studies, there is the underlying assumption that it is in some sense trivial to design mathematical fitness functions that can be used by the evolutionary algorithm to guide the development of robot controllers to task achieving behaviours. Yet, in some cases it might be difficult to think of the right fitness function before doing empirical testing, and some researchers [6], [8] do indeed suggest that some kind of shaping is necessary in the process of evolving robot behaviours to achieve some task. These difficulties lead us to propose the evolvable behaviorbased system, that combines the advances of evolutionary robotics and behaviorbased robotics in an attempt to avoid the necessity of describing complex fitness function. However, we still need to design mathematical fitness functions at some level. Further, the difficulties in describing adequate fitness functions (based on extensive studies of the problem domain), are seen by us as one of the main reasons why practically no researchers in the evolutionary robotics field have achieved truly complex robot behaviours, yet. Indeed, we will show here that most of the simple robot behaviours that have been developed by researchers in the evolutionary robotics field can be developed by children! Of course, given the right developmental tool.
Since our goal was to allow children to develop robot controllers for their individual ``needs'', we could not use the traditional evolutionary robotics approach, since it would require the children to know how to design mathematical fitness functions. Another possibility would be to use a system such as LEGO Dacta that has been developed to ease children's access to development and play with motorised constructions. In the case of LEGO Dacta, the children have to program the control in *LOGO. As with any traditional programming language, this is difficult for children. However, it might be justified in the case of LEGO Dacta, since LEGO Dacta is an educational tool to be used in schools, and to give children both programming skills and knowledge about control. As a playtool concept, the approach of using traditional programming for controlling motorised LEGO constructions might fail. The reason for this is that children will have to go through a very long process in order to learn the programming language before being able to make just the most simple controllers. Even when the programming language is learned, there is the problem of typing and other errors, and debugging will have to take place. So it will take a lot of efforts before children can actually get down to playing with the motorised LEGO construction, if ever. The fact is that it is too difficult for children to control motorised LEGO constructions with traditional programming! This is even further worsened when children are to construct LEGO robots, since these have a more complicated environmentsensormotorcontrol system interaction. We will here describe an approach to the development of LEGO robot controllers that overcomes the problems with traditional programming. In fact, we have constructed a simulator so that there is no programming involved for the enduser, and therefore it is much easier for children to use. The general idea is an Interactive Evolutionary Robotics approach by which children can develop robot controllers in the simulator by choosing among different robot behaviours that are shown on the screen, and then, when they are satisfied with the simulated robot's behaviour, download the developed control system to the real LEGO robot and further play with it in the real environment. The interactive evolutionary robotics approach is inspired by our previous work using interactive genetic algorithms to evolve simulated robot controllers, facial expressions and artistic images (see e.g. [7], [9]). In this approach, there is no need of programming knowledge, since all the enduser has to provide is a specification of preference of the solu tions suggested graphically on the screen. Hence, there is no description of a fitness function, but the selection in the genetic algorithm is performed by the user.
Electronics
The electronic hardware was developed at the Department of Artificial Intelligence, University of Edinburgh. It is composed of the following items:
Sensors and actuators
Construction elements
The robots are built out of stanard LEGO Technics pieces. This means that except for the electronic boards and the light and IR sensors, the whole construction, including the chassis, the gears, the wheels, the bumpers, is made of LEGO.
A. Robot designs
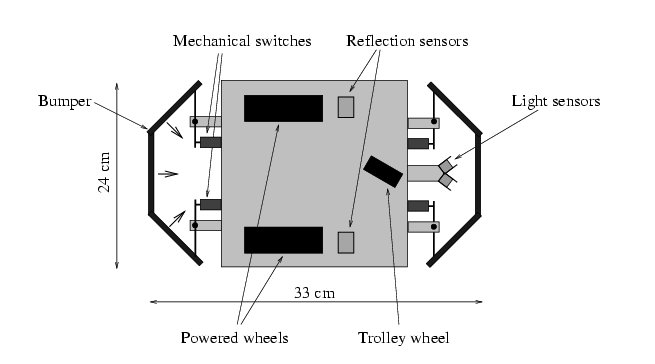
We built a couple of LEGO robots for testing purposes, but because of lack of space, we will only report on one design here. The robot was a stable jeeplike vehicle with three wheels (Figure 1). It had two powered wheels for locomotion and steering; the third wheel was a passive trolley wheel. The gear ratio between the motor and the powered wheels (8 cm in diameter) was 1/75. The robot had a good acceleration and reached a high top speed.
Fig. 1. Schematic (upper) view of the LEGO robot. The robot had a jeeplike shape and received sensory information from 4 mechanical switches mounted within two bumpers, 2 ambient light sensors at its front, and 2 reflection detectors under the chassis. © Lund et al. 1997.
The sensory input came from four mechanical switches Mechanical switches Reflection
sensors and four light sensors. The mechanical switches were mounted in two
touch sensitive bumpers at the front and the rear of the robot. The bumpers
were made of a lattice structure and continuously pressed the switches as long
as there was no shock (Figure 1). This type of construction has the advantages
to be light and to protect the switches from direct shocks. The sensitivity
of the bumper was determined by the elasticity of the rubber band keeping
the bumper in contact with the switches. Three directions of collision could
be detected by each bumper, namely left, right and frontal collisions.
The robot was able to measure the ground reflection with two light sensors mounted
under the chassis of the robot. Two reflection sensors were constructed by making
a device out of black cardboard in which a light sensor and a light bulb were
placed side by side and directed to the ground. The black cardboard was used
to prevent direct lighting of the sensor by the bulb and from external light
sources. These devices enabled the robot to distinguish beween black and white
grounds in a large variety of external lighting conditions.
The robot had also two light sensors mounted horizontally at its front. The
light sensors had an angle of approximately 80 degrees between them and enabled
the robot to locate light sources in its environment.

Fig. 2. Photo of the LEGO jeeprobot. It has bumpers on the front and the back, and light sensors underneath and on the front. © Lund et al. 1997.
As mentioned in [3], [5], it is possible
to build an accurate simulator that allows very good transference from simulation
to reality by basing the simulator on the robot's own samplings of sensor and
motor responses. The disadvantage is that data has to be collected. In the construction
of the simulator, this data had to be collected for the different sensors and
different motor configurations. For instance, we had to measure the motor response
for each individual LEGO robot design that we wanted to use in the simulator.
This is the disadvantage of the approach.
The sensor and motor data was collected in a similar way to that described in
[3], [5], and the collected data was put into
lookup tables that is used by the simulator to look up specific sensory readings
and displacements of the simulated LEGO robot.
The architecture of the control system that calculates the motor output given
a sensory input in the simulated and real LEGO robots was a feedforward neural
network that connected sensory input to motor output. The jeeplike LEGO robot
had 8 input neurons (4 bumpers and 4 light sensors), and the output was coded
in 6 output neurons. However, in some experiments, we used only 2 of the light
sensors (those on the bottom of the LEGO robot), and then we have only 6 input
neurons, 6 output neurons, and 6 bias units. In a total, this gave 42 connection
weights.
In order to obtain a controller that guides the LEGO robot to perform a desired
task, one will have to choose the right values for the 42 connection weights
in the feedforward neural network control system. In a sense, this corresponds
to finding a specific point (or region) in a 42 dimensional space. This is,
of course, impossible for children (and most adults). So therefore, we used
an interactive genetic algorithm to develop these connection weights. This algorithm
allowed children to develop the connection weights (i.e. the control system)
by choosing among robot behaviours shown on the computer screen. The interactive
genetic algorithm in the simulator works as follows.
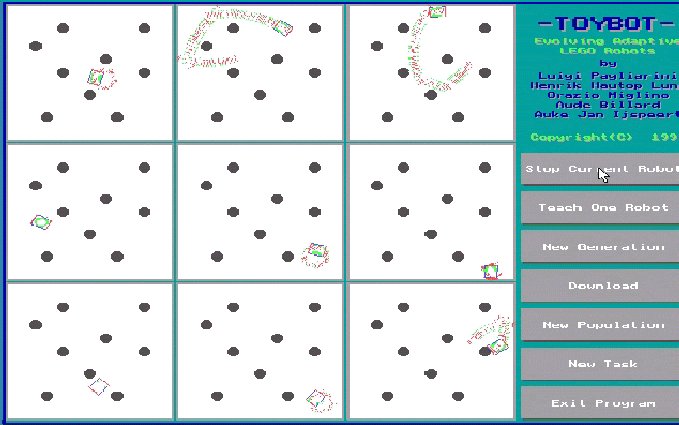
The simulator allows different population sizes, but let us here look at a population
of 9 robots. These 9 robots are placed in their copies of the environment. The
9 similar environments are shown on the screen at the same time (see Figure
3). Initially, the 9 robots in the population (generation 1), may have connections
weights generated at random or loaded from a set of previously saved connection
weights. The first of the 9 robots is put into the first environment. The robot
will produce reactions based on the connection weights of the neural network
control system and the sensory inputs. These reactions (movements) of the robot
are shown in the first environment on the screen. After this robot has run around
for a given time, the second robot is put into the (similar) second environment,
and the produced movements are shown on the screen. This is done for all 9 individual
robots. Hence, at this moment, the child has seen the 9 robots moving around
in each their environment one after another. Let us look at the example where
the robots' neural network control systems are generated at random. Some of
the robots will differ in their behaviour, since the connection weights in the
neural networks differ. The child might like some of these behaviours and dislike
others. Based on such an evaluation where the child shows preferences, the preferred
robots in the population can be chosen to reproduce. The child can, for instance,
choose 3 different ones, or choose the same robot 3 times.
In the reproduction phase, the 3 selected robots will be copied 3 times each
in order to produce the next generation (generation 2) of 9 robots. However,
as the neural network control systems are copied, mutation will be applied to
10% of the connection weights chosen at random. If a weight is selected, it
will have added a value chosen at random in the interval [10,10]. Hence, the
new generation of robots will be similar to their parents because they are copies,
but they will also differ to some degree because of the mutation.
The new generation of 9 robots is shown on the screen, one robot after another,
as was the case with the previous generation. The child can then again select
the 3 preferred robots and they will reproduce through copy and mutation to
make the next generation (generation 3). This loop can continue until the child
is satisfied with the obtained behaviour of the LEGO robot. It is important
to note, that the way the LEGO robots change is based on the child selecting
which ones to reproduce according to the child's individual preferences, and
based on the mutations.
 |
 |
 |
 |
Fig. 3. The population of 9 robots placed in each their (similar) environment. Here, the environment contains a number of round obstacles. The trajectory of each robot is shown in each of the 9 environments. The figures represent generation 1, 3, 5, and 7 of an evolutionary process. Here, the user is able to evolve successful obstacle avoidance for the LEGO robot within 7 generations. © Lund et al. 1997.
Another way to change a LEGO robot's behaviour is to develop a single LEGO robot's behaviour rather than develop on a whole population. If this option is chosen, an enlarged image with the environment and robot will appear on the screen (see Figure 4). The robot will start moving around in this environment, just as it did when the whole population was presented. Now, if the child dislikes a movement of the robot (e.g., the robot gets stuck when hitting into a wall), the child can press a "Bad" button. This will immediately change the underlying neural network control system of that robot. But, in this case, the change does not happen at random. The system keeps a record of the last input to the robot, and it is the connections weights going out from the input neurons that were activated that are changed (with random portions). In the case where the robot hits into the wall with the front left bumper, it will be the connection weights going out from the input unit for front left bumper that are changed. Hence, the reaction upon a bump with the front left bumper is changed. Each time the "Bad" button is pressed, there is also a slight chance of the bias connections being changed, resulting in a change in the default behaviour.
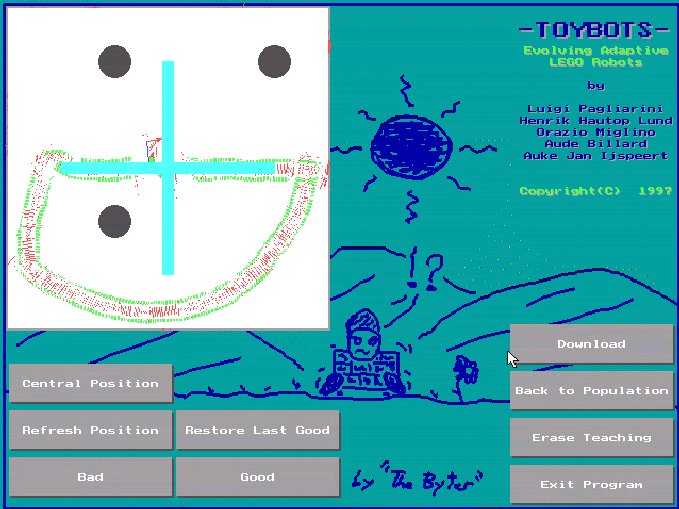
Fig. 4. The enlarged environment in which the child can train a single LEGO robot through reinforcement learning. The control system of the LEGO robot is changed every time the "Bad" button is pressed. In this environment there are two lines on the floor and 3 round obstacles. © Lund et al. 1997.
When the child is satisfied with the behaviour obtained in the teaching process,
the child can return to the whole poplation. The trained robot keeps the trained
network, and can then, eventually, be selected to reproduce. In this way, we
allow a Lamarckian evolution that consists of characeristics being learned during
lifetime being inherited over evolution. We definitely do not support such
a theory for natural evolution, but it has proved to be a very powerful tool
as a means for fast development of LEGO robots.
In a sense, what this type of reinforcement learning does is to make a guided
search in specific regions. In the case with the bump with the front left bumpers,
the algorithm performs a search on the weights connecting that input unit to
the output units, and the search is made only on these weights. It seems fast
to find a solution, because the dimension of the search space has been limited.
This is not a traditional reinforcement learning algorithm, but we found that
it works very well and quickly, at least for the simple tasks of the LEGO robots.
In order to speed up development time, we have also made some preevolved populations
of robot controllers that the children can choose from as the starting population.
After having chosen the specific environment to play with (Figure 5), the children
can then choose 1 out of 5 different populations of robots as the starting population.
These populations of neural network controllers have been evolved using the
same simulator, but with a fixed fitness formula for each behaviour, and hence
have (previously) run automatically for 100300 generations. With these preevolved
populations, children can start the development from a certain starting point
that includes some of the characteristics of the robot that the child might
like to evolve. This is instead of starting from a randomly chosen starting
point, from where it might take long time to develop something sensible and
interesting for the individual child.
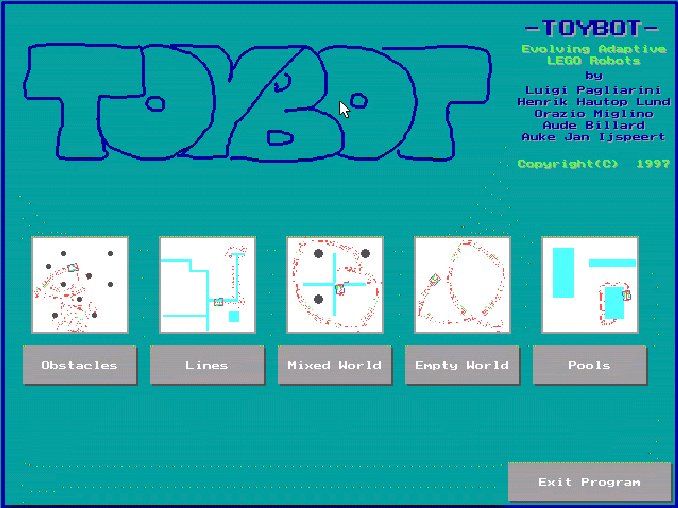
Fig. 5. The initial screen in the LEGO robot simulator. Here, children can choose between 5 different environments. © Lund et al. 1997.
The selection of individuals from the preevolved population of 100 neural network controllers works as follows. When creating the initial population, there is a 1% probability of taking a preevolved neural network (from the 100 preevolved in that population) against 99% probability of creating a neural network controller with random weights. The same thing happens when doing user guided reproduction. The user chooses the, for example, 3 LEGO robots (neural networks) to reproduce. When making reproduction (+ mutation), in most cases (99%) the algorithm copy the neural network chosen by the user and mutate it, while in 1% of the cases, instead of making mutation, the algorithm picks up a preevolved neural network from the above mentioned preevolved population.
We performed a series of experiments with the interactive evolutionary robotics approach described above, and had many children play with the LEGO robots. As expected, it turned out to be very simple to evolve exploratory behaviours, different kinds of obstacle avoidance, line & wall following, etc. and combinations between such simple behaviours. Figure 3 in the previous section showed the development of obstacle avoidance in a cluttered environment within only 7 generations. Hence, within minutes, children can develop a wide range of the robot behaviours that has traditionally been evolved in the field of evolutionary robotics. This is due to the use of the interactive evolutionary robotics approach combined with reinforcement learning. Indeed, with this approach children do not need to have any programming skills whatsoever! All that is demanded is that the child specify individual preferences in order to develop robots according to their individual taste. As the simulator is built now, even though children can develop a wide range of their own robot behaviours, there is a limitation, since we as designers have provided 5 specific environments and a specific neural network topology. Future extension might involve development of neural network topology and allowing children to design their own environments in the simulator, as they do in the real world. From an engineering point of view, observing unskilled children developing robot behaviours to the same level of complexity of what researchers have achieved so far in the evolutionary robotics community must in some way be frustrating for these researchers (including ourselves).
Materials and facilities were provided by the LEGO Group, the Danish National Centre for IT Research -- CIT, the National Research Council, Rome, Italy, and the University of Edinburgh.
[1] W.P. Lee, J. Hallam, and H. H. Lund. A Hybrid GP/GA Approach for Coevolving Controllers and Robot Bodies to Achieve FitnessSpecified Tasks. In Proceedings of IEEE Third International Conference on Evolutionary Computation, NJ, 1996. IEEE Press.
[2] W.P. Lee, J. Hallam, and H. H. Lund. Applying Genetic Pro gramming to Evolve Behavior Primitives and Arbitrators for Mobile Robots. In Proceedings of IEEE Fourth International Conference on Evolutionary Computation, pages 501--506, NJ, 1997. IEEE Press.
[3] H. H. Lund and J. Hallam. Evolving Sufficient Robot Controllers. In Proceedings of IEEE Fourth International Conference on Evolutionary Computation, NJ, 1997. IEEE Press.
[4] H. H. Lund, J. Hallam, and W.P. Lee. Evolving Robot Morphology. In Proceedings of IEEE Fourth International Conference on Evolutionary Computation, NJ, 1997. IEEE Press. Invited paper.
[5] H. H. Lund and O. Miglino. From Simulated to Real Robots. In Proceedings of IEEE Third International Conference on Evolutionary Computation, NJ, 1996. IEEE Press.
[6] S. Nolfi and D. Parisi. Evolving nontrivial behaviors on real robots: A garbage collecting robot. Robotics and Autonomous Systems, 1997. To appear.
[7] L. Pagliarini, H. H. Lund, O. Miglino, and D. Parisi. Artificial Life: A New Way to Build Educational and Therapeutic Games. In C. Langton and K. Shimohara, editors, Proceedings of Artificial Life V, pages 152--156, Cambridge, MA, 1997. MIT Press.
[8] S. Perkins and G. Hayes. Incremental acquisition of complex behaviour using structured evolution. In Proceedings of the Inter national Conference on Artificial Neural Networks and Genetic Algorithms '97. SpringerVerlag, 1997. To appear.
[9] V. Vucic and H. H. Lund. SelfEvolving Arts --- Organisms versus Fetishes. Muhely Hungarian Journal of Modern Art, 104:69--79, 1997.